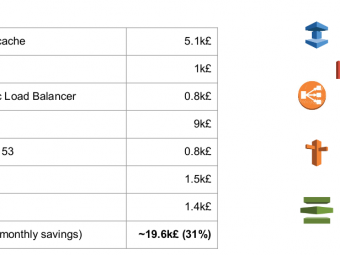
How to reduce AWS costs
Este texto é de cariz técnico e está escrito em Inglês We’ve decided to do a more in-depth article o...
Este texto é de cariz técnico e está escrito em Inglês We’ve decided to do a more in-depth article o...
Este texto é de cariz técnico e está escrito em Inglês A VPC Endpoint is a service that enables you...
Este texto é de cariz técnico e está escrito em Inglês We’ll be at AWS Summit Madrid for n...
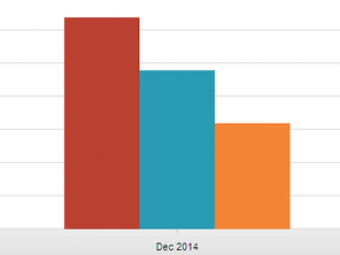
Este texto é de cariz técnico e está escrito em Inglês This looks like something out of Captain Obvi...
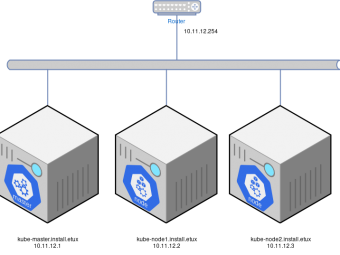
Este texto é de cariz técnico e está escrito em Inglês In this post I will try to describe a Kuberne...
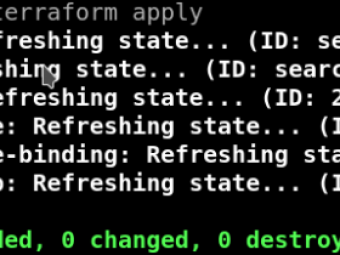
Este texto é de cariz técnico e está escrito em Inglês We’re always searching new ways of implementi...
Este texto é de cariz técnico e está escrito em Inglês Currently playing with Red Hat’s Kubernetes f...